January 2019
Back in 2015, a statewide archaeological predictive model was created that estimated high, moderate, and low probability areas for pre-contact archaeological sites (Harris et al 2015). At the time of publication, Pennsylvania became the second state in the US to have such a statewide model, the other being Minnesota. Prior to introduction of the model and its ultimate disposition as layers within the Cultural Resources GIS system, project-specific predictive models had been developed, but nothing on this scale had been attempted. But, building a model and trusting a model are quite different things. Since 2015, both the Pennsylvania State Historic Preservation Office and the Pennsylvania Department of Transportation have made forays into testing the model against site data collected after the model was created. These well intentioned peeks under the hood offer some insights regarding the utility of the model, but do not address the key question, “Can archaeologists use it?”
A Bit of History
In 2013, FHWA, PennDOT and its consultant URS Corporation (now AECOM) partnered with the PHMC and FHWA to produce a statewide archaeological predictive model for sites related to Native Peoples in Pennsylvania prior to European contact. The resulting model creates two GIS (geographic information system) sensitivity layers that show where there is a high probability for these sites and where there is a moderate probability for these sites. The remaining space is interpreted as low probability. The model results are currently being used by metropolitan and rural planning organizations (MPO/RPO) in planning transportation projects. The model provides inputs for PennDOT Connect Level 2 screening forms, and is an improvement over previous inputs that were based only on proximity to known archaeological sites. In addition, the predictive model will be used to choose alternatives in larger EIS-level projects, rather than independently developing a predictive model for each project.
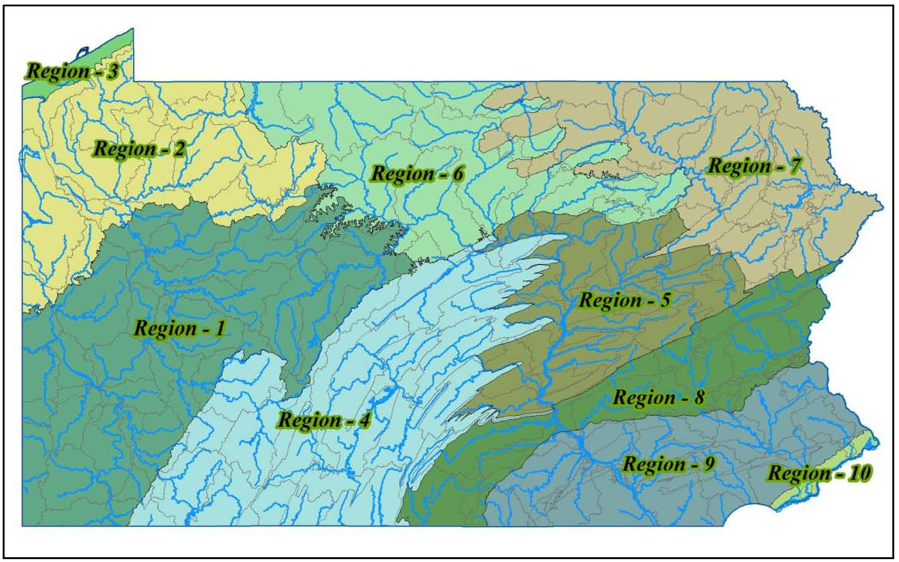
Pennsylvania was divided into 10 geographic regions for the purposes of developing models that responded to local conditions. Within each region, study areas based on watershed and topographic position were created totaling 132 study areas statewide. For each study area, a customized predictive model was created. As with most inductive predictive model development, known archaeological site data was used to build the models. Known archaeological site data was also used to test and further refine the models. Environmental variables were used in the analysis, including distance to 3rdand 4thorder streams, distance to drainage head, nearness to wetlands, slope and average soil water capacity, amongst others. In this instance, the algorithms used were: backwards stepwise logistic regression, multivariate adaptive regression splines (MARS), and random forest (RF).
The set of 132 archaeological predictive models created for this project (hereafter known as the Model) is one of the largest and most detailed ever published. The only other statewide model of this type is for Minnesota. While Pennsylvania is half the size of Minnesota, the Model is at a finer grain (10m cells versus 30 m cells) resulting in roughly twice the number of cells in Pennsylvania than in Minnesota. The Model is among the first published using both the MARS and RF algorithms in archaeology, and certainly the first on this scale. The reports of how the Model was developed can be found in 7 volumes on PennDOT’s cultural resources page, the last volume (Number 7) being the synopsis of the study.
Many Caveats
There are myriad issues associated with archaeological predictive models that I don’t want to get into now. Some of these include:
- Inductive versus deductive-derived models. Deductive models have the greatest chance of having explanatory power, but the entire field is underdeveloped. Most predictive models in the US over the last 30 years have been inductive-derived. Throw a passel of environmental variables into a regression blender and see what comes out. PennDOT and PA SHPO went with inductive-derived models, sacrificing explanatory power for a better chance at finishing the project.
- Uneven survey across the state, both by setting and by region. Some locations are well surveyed (along rivers); some not so much (upper thirds of mountains and hills). Clearly, regions with better data yield better results.
- Variable methods to identify archaeological sites, e.g. surface survey, shovel tests, reporting by avocationals, etc. Of course you want apples to apples. In the case of this study, the hope was that quantity (25,000 known sites) made up for variable quality.
- Lack of clarity as to what was actually surveyed, i.e., what patches of ground constituted surveyed versus non surveyed. The data set used to build the Model came from over 60 years of work. This is not a trivial issue, as even site boundaries can be squishy, but this lack of precision was accepted into the study.
Again, each is worthy of its own discussion, but not today. Instead, I would like to confront the issues of model testing and model validation. By model testing, I mean statistical testing. By model validation, I mean acceptance and use in the archaeological community, i.e., a belief that the model is worth something.
Statistical Testing
Statistical model testing is predicated on the estimation of error in the model. Often inductive models make it difficult to estimate error since there isn’t an independent data set available for testing purposes (Verhagen 2008). A way to approach estimating error is through resampling and cross-validation techniques, such as bootstrapping techniques. These were used in the development of the Pennsylvania Model.
For inductive models, we would want the model to be both accurate and precise, since the door to explanatory power is closed. A highly accurate model would identify all locations where there are archaeological sites. A highly precise model would identify archaeological sites in the smallest area possible. There are really no models that are perfectly accurate and precise. The Kvamme gain measure combines accuracy and precision concepts into a single number. In the case of the Pennsylvania Model, the overall Kvamme gain was 0.701. Comparable peer models analyzed by Harris et al had Kvamme gain values averaging 0.432. So far, so good.
The Pennsylvania Model was operationalized into mapped sensitivity zones of high and moderate probabilities, and by inference low probabilities. There is nothing inherent in the Model or in the Kvamme gain that specifies high, moderate, or low probabilities. Nor, frankly are there any quantified definitions within their current use in Pennsylvania archaeology. Yet, this distinction has meaning in practice for compliance archaeology, and any model that would be used in compliance would necessarily need to make these distinctions. In order to be able to map high, moderate, and low zones PennDOT and the PA SHPO had to make some subjective decisions. Ultimately, the project team settled on a definition of Low probability of having less than 1/3 of predicted sites being located in more than 2/3 of the geographic area. High probability was defined as having a prevalence of 0.1, or that predicted sites would be contained within 10% of the geographic area. What was in between was classified as Moderate probability.
“Testing” Work to Date
By setting metric standards for High, Moderate, and Low probabilities and by having a reasonable estimate of error, it became possible to compare two models, side-by-side and test whether one is significantly better than the other. Given that inductive models are not explanatory, the only progress in model building would be this kind of side-by-side test. Between 2014 and 2017, PennDOT interns worked closely with PA SHPO Staff to see how well the model was performing. Results from compliance surveys reported after the completion of the model, i.e., independent data, were fair game (Conway et al 2018). The preliminary results from this analysis supported the efficacy of the Model. It seemed to work. A second focus of the study was in comparison of the different site discovery methods employed by archaeologists, basically the 3rdcaveat above. Unfortunately, no firm conclusions could be made due to the highly variable nature of testing methods and other idiosyncratic events that affected results.
Coming back to the premise of statistical testing, the question always comes back to tested against what? The intern work was interesting and useful, but did not presume to be statistically rigorous. For both the MnModel and the Pennsylvania Model, during model development, statistical comparisons were made against random calls, as a baseline. Hopefully, any model would work better than coin flips, and in both cases, the models were statistically proven to do that with honors. For the next generation of models to be developed using fresh data, the new model can be measured side-by-side against the old model to see if it is better, not just by feel, but statistically better. For now that test will need to wait. To summarize, we have a Model that appears to be performing and works better than random calls, despite numerous caveats.
If You Build It, Will They Come?
The two questions of testing and validation: tested against what; and, will archaeologists use it? could potentially be resolved at the same time. That the Model was tested against random calls is certainly a start, but the acid test would be against the pool of archaeologists currently making decisions on high, moderate, and low probabilities on their own. Essentially this would be comparing machine decisions against human decisions. I believe the true test of any archaeological predictive model is whether it is significantly better than what we are doing today in the field on our own with our own puny little homo sapiens brains. Certainly, Alan Turing thought that this was the true test of machine intelligence, vis a vis the Imitation Game. Could an independent observer tell the difference between answers given by a human versus machine?
The utility of this approach is that it does not require the current Model to be perfect, only better than the current standard, which is best professional judgement. If it can be demonstrated that the Model, or any of its 132 separate individual models is finding archaeological sites at a higher rate in a smaller survey footprint, then validation by the archaeological community will follow.
For us to get to the point where we could answer the Imitation Game question, two changes need to occur in the recording of archaeological surveys. First, all survey archaeologists would be required to state up front what precisely is their survey area, ideally tied into GPS coordinates. Within those survey areas, they would be required to divide the survey area into high, moderate, and low probabilities prior to survey and to report this information with the survey results. To the degree that survey methodologies would change within the survey area, they would also need to report this information also with polygons. For example, if there is a plowed field within the survey area and it is covered by foot survey but the remainder of the survey area is shovel tested at 15m intervals, that would need to be reported. Albeit this is a very fine grained reporting; however, we are at the point with technology that tablets in the field could record each and every shovel test pit or every minor polygon accurately and quickly.
Secondly, each survey archaeologist would be required to honestly assess probabilities prior to viewing the Model results, in order to make it a fair blind test. Cheating is verboten. This could be managed at the PA SHPO end by requiring each survey to submit its human generated predictions before gaining access to the Model generated predictions. Obviously, this would require some additional programming into the CRGIS and some additional permission steps, but it is doable.
Because the probability models are now artificially sliced up into 10m or 30m squares, but originally were continuous surfaces, it could be possible to customize the model expectations for each independent survey, using an algorithm similar to what was used to create the 10m or 30m probability squares in the first place. All that is required is that the boundaries of the survey area be captured accurately and that a consistent algorithm be applied to slice that polygon into the high, moderate, and low probability polygons contained within the larger project area polygon.
One last intriguing possibility in organizing data in this way is to make the test less reliant on identifying archaeological sites and boundaries and instead looking at point specific (i.e., shovel test pit) results. When considering shovel test pits, or 1×1 m units, the whole exercise becomes one of point sampling. That location has a high, moderate, or low probability from the Model and from the archaeologist. The result is either negative or positive (nominal data), or artifact counts (ratio), each with its own suite of statistical tools. This test might do away with the concept of site entirely and focus on intensity of presence on the landscape, i.e., some spots are more intensively utilized than others.
Unfinished Business
Since the Model was introduced to the archaeological community in 2015, survey work has proceeded apace. If the approach outlined above is to be pursued, then reporting methodologies and consistent human predictions of high, moderate, and low need to start yesterday. It may be possible to data mine previous surveys through interview and reconstruction of notes, but that would be a labor intensive operation.
Changes to the CRGIS to produce customized probability zones based on revised algorithms would require some programming changes to the system that are not currently anticipated. In addition, survey data capture would also require programming changes in order to acquire that fine-grained data for analysis, and changes to permission rules to withhold Model predictions until human generated expectations are submitted. As with any government-run system, a long lead time would be needed to effect those changes.
In the meantime, it would be prudent for either PennDOT or the PA SHPO to obtain the services of a statistician to help with research design for testing the model. This would ensure that the data collection and analyses would pass scientific muster.
This is no small proposal, and would require adjustments in thinking and behavior within the archaeological community, not just adding some programming code. I do believe that until these changes or something like them are instituted, we will not make progress on the original Model, and would risk the waste of all the good work to date that it has engendered.
Note:Because of my close involvement with the development and launch of the Model, I feel it is important to state that these comments are my own and do not reflect the views of FHWA, PennDOT, or the PA SHPO.
References
Conway, Jessica, Clare Farrow, and Haley Hoffman
2018 Testing the Pennsylvania Precontact Predictive Model. Paper presented at the 83rdAnnual Society for American Archaeology Meetings, Washington, DC.
Harris, Matthew D., Robert G. Kinsley, and Andrew R. Sewell
2015 Archaeological Predictive Model Set. Final Report.Pennsylvania Department of Transportation, Contract 355101, Project 120205. Harrisburg.
Verhagen, Phillip
2008 Testing archaeological predictive models: a rough guide. In A. Poslunschny, K. Lambers, and I. Herzog (eds), Layers of Perception. Proceedings of the 35thInternational Conference on Computer Applications and Quantitative Methods in Archaeology (CAA), Berlin, Germany, April 2-6, 2007. Kolloquien zur Vorund Frhugeschichte,Vol. 10:285-291. Bonn.
